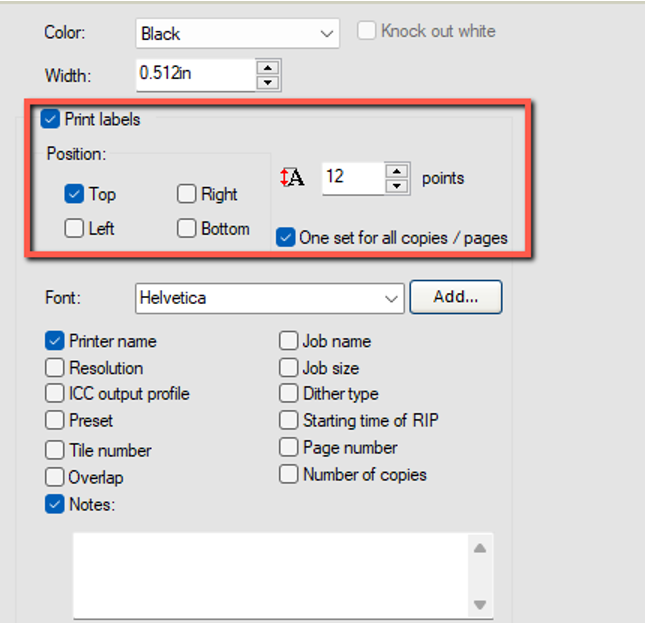
Wals Roberta Sets Upd
Introduction
The World Atlas of Language Structures (WALS) is a comprehensive online database that documents structural properties of languages worldwide. It was launched in 2005 and has since become a valuable resource for linguists, researchers, and language enthusiasts. WALS provides a unique platform for exploring the diversity of languages and their structures. One of the exciting developments in the realm of natural language processing (NLP) and artificial intelligence (AI) is the Roberta model, a type of transformer-based language model. In this essay, we'll explore the WALS database, the Roberta model, and discuss how they relate to setting up language structures.
WALS: A Database of Language Structures
The WALS database is an impressive collection of linguistic data, featuring over 2,500 languages and more than 100 language structures. The database is designed to facilitate research and exploration of language diversity, providing a wealth of information on phonology, grammar, and lexicon. WALS allows users to search, browse, and visualize language data, making it an invaluable resource for comparative linguistics, language typology, and language documentation.
The WALS database is curated by a team of experienced linguists who carefully evaluate and document the structural properties of languages. The data is presented in a user-friendly format, with clear explanations and examples. Users can access maps, tables, and figures that illustrate the distribution of linguistic features across languages and geographical regions.
Roberta: A Transformer-Based Language Model
Roberta is a type of transformer-based language model developed by Facebook AI in 2019. The model is designed to improve the performance of NLP tasks, such as language translation, sentiment analysis, and text classification. Roberta is trained on a massive corpus of text data and uses a multi-task learning approach to learn contextualized representations of words.
The Roberta model has achieved state-of-the-art results in various NLP tasks, demonstrating its effectiveness in understanding and generating human-like language. The model is also highly customizable, allowing developers to fine-tune it for specific applications and domains.
Setting Up Language Structures with WALS and Roberta
The intersection of WALS and Roberta presents exciting opportunities for setting up language structures. By combining the comprehensive linguistic data from WALS with the powerful language model Roberta, researchers and developers can create innovative applications and tools.
One potential application is the development of more accurate language models for low-resource languages. Many languages, especially those with limited linguistic documentation, can benefit from the WALS database and Roberta's capabilities. By leveraging WALS data and fine-tuning Roberta on a specific language, developers can create more effective language models that better capture the nuances of that language.
Another area of application is language typology and language comparison. WALS provides a rich source of data for comparing language structures, while Roberta can help analyze and visualize these comparisons. By integrating WALS data with Roberta's language understanding capabilities, researchers can gain deeper insights into language typology and the evolution of language structures.
Conclusion
The combination of WALS and Roberta presents a powerful toolset for setting up language structures. By leveraging the comprehensive linguistic data from WALS and the advanced language understanding capabilities of Roberta, researchers and developers can create innovative applications and tools that improve our understanding of language diversity.
The WALS database provides a unique resource for exploring language structures, while Roberta offers a state-of-the-art language model for NLP tasks. Together, they have the potential to advance our understanding of language and facilitate the development of more effective language technologies. As researchers continue to explore the intersection of WALS and Roberta, we can expect to see exciting developments in the fields of NLP, AI, and linguistics.
Future Directions
The integration of WALS and Roberta is just the beginning of a promising research direction. Future studies can explore various applications, such as:
- Low-resource language modeling: Using WALS data and Roberta to develop more accurate language models for languages with limited linguistic documentation.
- Language typology: Integrating WALS data with Roberta's language understanding capabilities to analyze and visualize language comparisons.
- Language documentation: Using WALS and Roberta to support language documentation efforts, particularly for endangered languages.
As researchers continue to push the boundaries of WALS and Roberta, we can expect to see innovative applications and a deeper understanding of language structures. The intersection of these two technologies has the potential to transform the field of linguistics and NLP, enabling new discoveries and applications that can benefit society as a whole.
The phrase "WALS Roberta sets upd" appears to refer to the intersection of linguistic typology and modern Natural Language Processing (NLP). Specifically, it likely refers to research using the World Atlas of Language Structures (WALS) to evaluate or "update" the multilingual capabilities of RoBERTa-style models.
Below is an overview of the key concepts and research areas relevant to this topic: 1. The World Atlas of Language Structures (WALS)
WALS is a large database of structural (phonological, grammatical, lexical) properties of languages gathered from descriptive materials (such as reference grammars) by a team of 55 authors.
Typological Features: It documents features like word order, number of genders, and the presence of specific phonemes across thousands of languages.
Research Utility: In NLP, WALS is frequently used as a benchmark to see if AI models "understand" or respect the actual structural diversity of human languages. 2. RoBERTa and Multilingual Models
RoBERTa (Robustly Optimized BERT Pretraining Approach) is a transformer model that improved upon BERT by training on more data with better hyperparameters.
Multilingual Variants: Models like XLM-RoBERTa are trained on hundreds of languages simultaneously. wals roberta sets upd
"Sets Up": Researchers often use WALS to "set up" or configure benchmarks to test these models. For example, they might select "source languages" for cross-lingual transfer based on how linguistically close they are to a "target language" according to WALS metrics. 3. Recent Research Trends ("The Update")
Recent academic "essays" and papers have argued that for generative linguistics and NLP to remain relevant, they need a "serious update". This involves:
Standardized Datasets: Utilizing standardized empirical evidence (like WALS data) to evaluate if models like RoBERTa are truly learning universal linguistic patterns or just surface-level statistical cues.
Cross-Lingual Benchmarking: Using WALS-reliant metrics to choose linguistically-closest languages for fine-tuning, which helps in low-resource settings where data for specific languages (like Tagalog or Old Irish) is scarce.
If you are looking for a specific essay title or a set of instructions for a coding "setup," please provide more context regarding the specific author or the programming environment (e.g., Python, HuggingFace) you are using. calamanCy: NLP pipelines for Tagalog - Lj Miranda
Unlocking the Power of WALS: Roberta Sets and UPD
Wide & Deep Learning (WALS) is a powerful machine learning framework developed by Google that combines the strengths of both wide learning and deep learning models. One of the key components of WALS is the use of embeddings, which enable the model to capture complex relationships between categorical features. In this article, we'll dive into the world of WALS and explore the concepts of Roberta sets and UPD (Universal Product Descriptor), and how they can be used to supercharge your WALS models.
What is WALS?
WALS is a hybrid model that combines the benefits of wide learning and deep learning to improve the accuracy and efficiency of machine learning models. The wide component of WALS is a linear model that captures high-order interactions between features, while the deep component is a neural network that learns complex representations of the input data. By combining these two components, WALS models can learn both linear and non-linear relationships between features, making them particularly effective for tasks such as recommendation systems, ranking, and classification.
What are Roberta Sets?
Roberta sets are a type of categorical feature embedding that can be used in WALS models. The term "Roberta" comes from the popular language model BERT (Bidirectional Encoder Representations from Transformers), which was developed by Google. Roberta sets are inspired by the BERT architecture and are designed to capture contextual relationships between categorical features.
In traditional WALS models, categorical features are typically represented as one-hot encoded vectors, which can lead to the curse of dimensionality and make it difficult to capture complex relationships between features. Roberta sets, on the other hand, use a learned embedding to represent each categorical feature, allowing the model to capture nuanced relationships between features.
What is UPD?
UPD, or Universal Product Descriptor, is a standardized system for describing products and services. It was developed by GS1, a global standards organization, to provide a common language for describing products and services across different industries and geographies.
In the context of WALS, UPD can be used as a categorical feature that provides a rich source of information about products and services. By incorporating UPD into a WALS model, developers can leverage the standardized product descriptions to improve the accuracy and efficiency of their models.
Using Roberta Sets and UPD with WALS
So, how can you use Roberta sets and UPD with WALS to supercharge your machine learning models? Here are a few strategies to consider:
- Use Roberta sets to capture contextual relationships: By using Roberta sets to represent categorical features, you can capture nuanced relationships between features that might not be apparent through traditional one-hot encoding.
- Incorporate UPD as a categorical feature: By incorporating UPD into your WALS model, you can leverage the standardized product descriptions to improve the accuracy and efficiency of your model.
- Combine Roberta sets and UPD: One powerful approach is to use Roberta sets to represent categorical features and UPD as a additional feature that provides a rich source of information about products and services.
Benefits of Using Roberta Sets and UPD with WALS
There are several benefits to using Roberta sets and UPD with WALS:
- Improved accuracy: By capturing nuanced relationships between categorical features and leveraging standardized product descriptions, you can improve the accuracy of your WALS models.
- Increased efficiency: By using Roberta sets and UPD, you can reduce the dimensionality of your input data and improve the efficiency of your WALS models.
- Flexibility: Roberta sets and UPD can be used with a wide range of WALS architectures and can be easily integrated into existing models.
Real-World Applications
So, what are some real-world applications of WALS with Roberta sets and UPD? Here are a few examples:
- Recommendation systems: WALS with Roberta sets and UPD can be used to build highly accurate recommendation systems that take into account complex relationships between user behavior, product features, and context.
- Product classification: WALS with Roberta sets and UPD can be used to improve the accuracy of product classification models, allowing businesses to better categorize and recommend products to customers.
- Search ranking: WALS with Roberta sets and UPD can be used to improve the accuracy of search ranking models, allowing businesses to surface the most relevant results to users.
Conclusion
In conclusion, WALS with Roberta sets and UPD is a powerful combination that can be used to supercharge machine learning models. By capturing nuanced relationships between categorical features and leveraging standardized product descriptions, developers can build highly accurate and efficient models that drive business results. Whether you're building recommendation systems, product classification models, or search ranking models, WALS with Roberta sets and UPD is definitely worth considering.
In Natural Language Processing (NLP), the integration of WALS (World Atlas of Language Structures) with RoBERTa-based models is a specialized technique used to improve the performance of multilingual AI on diverse languages. Core Concepts Introduction The World Atlas of Language Structures (WALS)
WALS (World Atlas of Language Structures): A large database of structural properties (phonological, grammatical, and lexical) for languages worldwide. It is used to group typologically similar languages to aid in cross-lingual transfer.
RoBERTa (Robustly Optimized BERT Approach): A transformer-based model widely used for language comprehension. For multilingual tasks, versions like XLM-RoBERTa (XLM-R) are standard, as they are pre-trained on massive text datasets from 100+ languages. Integration and Updates
Recent research focuses on "updating" how these models process low-resource languages by injecting typological knowledge from WALS directly into the model's architecture or training data:
Linguistic Similarity Metrics: New metrics like qWALS (quantified WALS) integrate multiple features to measure language similarity more accurately than previous methods.
Zero-Shot Transfer: By informing a RoBERTa model about the grammatical structure (e.g., word order) of a target language via WALS data, the model can perform better on that language even if it has never seen it during training.
Language Embeddings: Researchers have released new sets of language representations and projected syntactic features to ensure AI models capture linguistically meaningful generalizations across approximately 7,000 languages.
Note on Unofficial Links: You may encounter unofficial download links (e.g., "wals roberta sets zip") on various forums. These often refer to pre-packaged data for specific research papers or community-developed fine-tuning sets; always verify these against official repositories like the ACL Anthology or arXiv.
The Past, Present, and Future of Typological Databases in NLP
The request "wals roberta sets upd" appears to refer to the World Atlas of Language Structures (WALS) and its data regarding definite and indefinite articles (often used as "sets" in linguistic analysis), likely in the context of training or fine-tuning a RoBERTa (Robustly Optimized BERT Pretraining Approach) transformer model.
Below is a complete article exploring how these cross-linguistic "sets" of grammatical data are used to update and enhance NLP models like RoBERTa.
Bridging Typology and Transformers: Updating RoBERTa with WALS Article Sets
In the evolving landscape of Natural Language Processing (NLP), the intersection of linguistic typology and deep learning has become a frontier for creating truly "language-aware" models. By leveraging the World Atlas of Language Structures (WALS), researchers are finding new ways to update RoBERTa sets, allowing the model to better understand the nuances of definite and indefinite articles across the world’s 7,000+ languages. 1. The Data Source: WALS and Grammatical Articles
The World Atlas of Language Structures (WALS) is a large database of structural properties of languages gathered from descriptive materials. One of its most critical "sets" for NLP is Chapter 37: Definite Articles and Chapter 38: Indefinite Articles.
Definite Articles: WALS tracks whether a language uses a word (like "the"), an affix (a suffix or prefix), or no article at all to code specificity.
The Problem: Traditional transformer models like BERT or RoBERTa are heavily biased toward English-like structures. Without specific updates, they struggle with languages that mark "definiteness" through tone, word order, or complex morphology. 2. RoBERTa: The "Robust" Transformer
RoBERTa is an iteration of the BERT model that removed the "Next Sentence Prediction" objective and trained on much larger datasets with longer sequences. While powerful, its "sets" of weights are initially optimized for the languages present in its training data (predominantly Indo-European). 3. Developing the "WALS-Updated" Article Set
To develop a complete article or model update using these datasets, developers follow a specific pipeline: Step A: Feature Extraction from WALS
Researchers map WALS feature codes (e.g., Feature 37A for Definite Articles) to the languages present in the RoBERTa training corpus. This creates a "typological vector" for each language. Step B: Fine-Tuning with Linguistic Constraints
Instead of just "learning from text," the model is updated to recognize that in certain languages, the absence of an article is a structural feature, not a missing word. This is particularly vital for:
Low-Resource Languages: Where text data is scarce, but WALS data is available.
Cross-Lingual Transfer: Using the WALS "article sets" to help a model trained on English understand a language like Swahili or Turkish. Step C: Outcome Prediction
Recent studies have shown that RoBERTa-assisted methodologies can even predict complex outcomes in unstructured text (such as medical operative notes) by better understanding the relationship between subjects and their "articles" or lack thereof. 4. Why This Matters for Global NLP
Updating RoBERTa with WALS data helps solve "linguistic distance" issues. Research indicates that the larger the linguistic distance between a speaker's native language and English, the harder it is for standard models to process their input accurately. By integrating the WALS article sets, we "shorten" this distance, creating models that are more inclusive of diverse grammatical structures. Chapter Definite Articles - WALS Online
This phrase appears to be a highly specific search string associated with illicit or adult-oriented content leaks, often found on file-sharing sites or in spam/bot-generated comments on forums and social media Brightspark Consulting Low-resource language modeling : Using WALS data and
It does not refer to a standard feature in legitimate technology, software, or academic research. Contextual Breakdown Wals Roberta
: Often refers to content related to a specific digital creator or model (Roberta Wals). : Typically refers to collections of images or videos.
: Short for "updated," indicating the latest version of a collection. "Full Feature"
: A term often used to advertise complete, unedited versions of such content. Brightspark Consulting While keywords like are prominent in AI (referring to a pre-trained language model
from Facebook/Meta), the specific combination "wals roberta sets upd" is not related to machine learning. Search results containing this string frequently appear alongside broken links, "hot" file descriptions, or spam threads on unrelated websites. Hugging Face RoBERTa - Hugging Face
WALS RoBERTa Sets (commonly found as WALS-RoBERTa-Sets-1-36.zip
) are a specialized collection of pre-configured datasets and model weights used in Natural Language Processing (NLP). They are primarily used to probe how multilingual models, specifically XLM-RoBERTa
, encode linguistic "DNA" like word order, grammar, and syntax across different language families. Core Overview The "Sets 1-36" refer to a specific grouping of 36 languages selected based on their documentation in the World Atlas of Language Structures (WALS)
. These sets are used to test if AI models "understand" the underlying structural rules of a language (e.g., "does this language put the verb before the object?") rather than just memorizing vocabulary. Massachusetts Institute of Technology 🛠️ Key Components WALS Integration
: Uses typological features (structural blueprints) from the World Atlas of Language Structures to categorize languages. Model Base : Built upon XLM-RoBERTa
, a transformer model trained on over 100 languages that serves as the "brain" for these experiments. The 36 Sets
: Represents a diverse cross-section of 9 language families and 20 language groups, including Indo-European, Altaic, and Uralic. Probing Tasks
: Specifically designed to see if a model can predict a language's identity or grammatical features based on sentence embeddings alone. 📈 Why This Matters Importance in NLP Research Language Identity
Helps researchers understand if models can distinguish between similar languages (e.g., Spanish vs. Italian). Cross-Lingual Transfer
Allows a model trained in English to apply "structural logic" to a low-resource language it hasn't seen much of before. Zero-Shot Learning
Enables the evaluation of how well a model performs on a new language without any specific training data for that language.
4. Practical code snippet (pseudo-PyTorch)
def wals_roberta(sentences, model, tokenizer, pca_components, alpha=1e-4):
emb = encode(sentences) # (n, d)
# Whiten by inverse singular values
U, S, Vt = torch.pca_lowrank(emb, q=pca_components)
S_inv = 1.0 / torch.sqrt(S**2 + alpha)
W = Vt.T @ torch.diag(S_inv) @ Vt # projection matrix
return emb @ W
Final Thoughts
The WALS Roberta setup offers a practical hybrid: the scalability and implicit‑feedback handling of WALS, plus the deep semantic understanding of RoBERTa. It’s particularly powerful for platforms where items arrive frequently and text is the primary descriptor. When implemented with careful regularization, this approach often outperforms pure collaborative or pure content‑based methods.
Information regarding these specific sets is generally confined to niche digital image communities and online archives rather than mainstream media or journalistic publications.
Because these terms are associated with specific digital collections, search results often point toward file-hosting services or unverified third-party blogs. There are no widely recognized articles or formal reviews available on this topic.
If the interest is in a different subject or a different person named Roberta, providing more context could help in finding relevant information. Cutting-edge kitchen knives - Scripps Ranch News
ivofer d868ddde6e https://coub.com/stories/3129393-left-4-dead-1-crack-download-better · trarho says: January 30, 2022 at 1:35 pm. Scripps Ranch News Cutting-edge kitchen knives - Scripps Ranch News
3. Interesting variant: Supervised WALS
- Learn scaling factors ( w_i ) using labeled STS data (contrastive loss).
- Keeps the interpretability of dimension weighting while adapting to task.
Limitations
- Text dependency – Requires rich textual metadata per item.
- Static encodings – Frozen RoBERTa may miss domain‑specific semantics unless fine‑tuned on task‑relevant text.
- Memory overhead – Storing 768‑dim embeddings for millions of items can be heavy (use quantization or dimension reduction).
1. What makes WALS RoBERTa interesting?
- Standard RoBERTa produces anisotropic token embeddings (unevenly distributed, dominated by frequent directions).
- WALS post-processes embeddings by scaling dimensions based on both their variance (length scaling) and angular distribution (weighted angle), leading to more isotropic and discriminative representations.
- Result: Better zero-shot transfer on STS without fine-tuning.
Review: WALS + RoBERTa Integration (The "upd" Approach)
Verdict: A High-Value Niche Resource for Linguistic AI
Integrating the World Atlas of Language Structures (WALS) with RoBERTa represents a significant step forward in grounding statistical language models in typological reality. While standard RoBERTa models excel at semantic and syntactic pattern matching, they often lack explicit knowledge of global linguistic diversity. A WALS-RoBERTa dataset bridges this gap, creating a model that is not just fluent, but linguistically aware.
Where RoBERTa Enters
RoBERTa (Robustly Optimized BERT Approach) is a transformer-based language model pretrained on massive text corpora. In this setup, RoBERTa is not used for sequence generation but as an item encoder:
- For each item (e.g., a product, article, or video), its title, description, or other text features are passed through a frozen or fine-tuned RoBERTa.
- The final hidden state (e.g.,
[CLS] token embedding) becomes a dense semantic vector – an item content embedding.
- This embedding initializes or regularizes the item factor matrix in WALS.
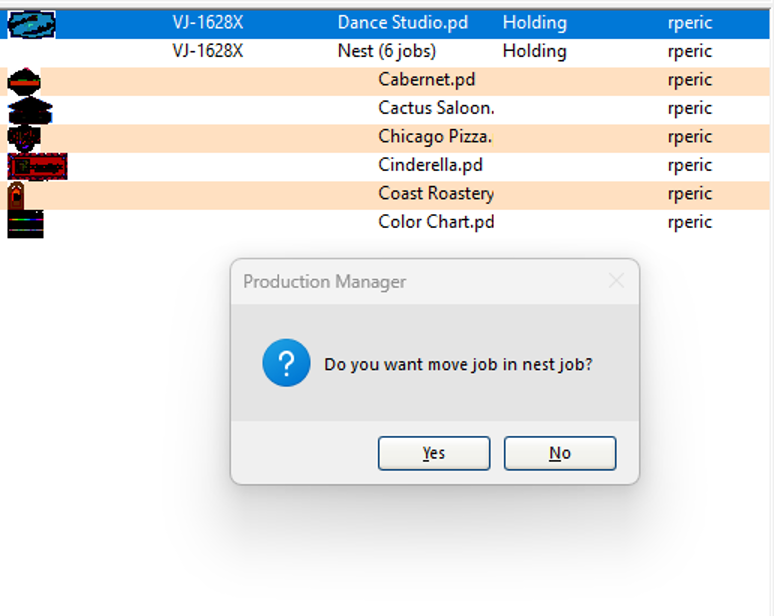
One of the many small improvements
we’ve made to enhance your user experience is the ability to
view thumbnails for jobs in the Production Manager queue.
Thumbnails can be enlarged when the mouse is hovered.
Adding to a Nesting Group
It is no longer necessary to un-nest
jobs when you want to add a new job or tile to the group. Simply
add the new job to the queue, then drag and drop to the nested
group.
There is now support for Kongsberg cutting table tiles in Flexi
and Production Manager. This includes support for barcodes, QR
codes, and data matrices.
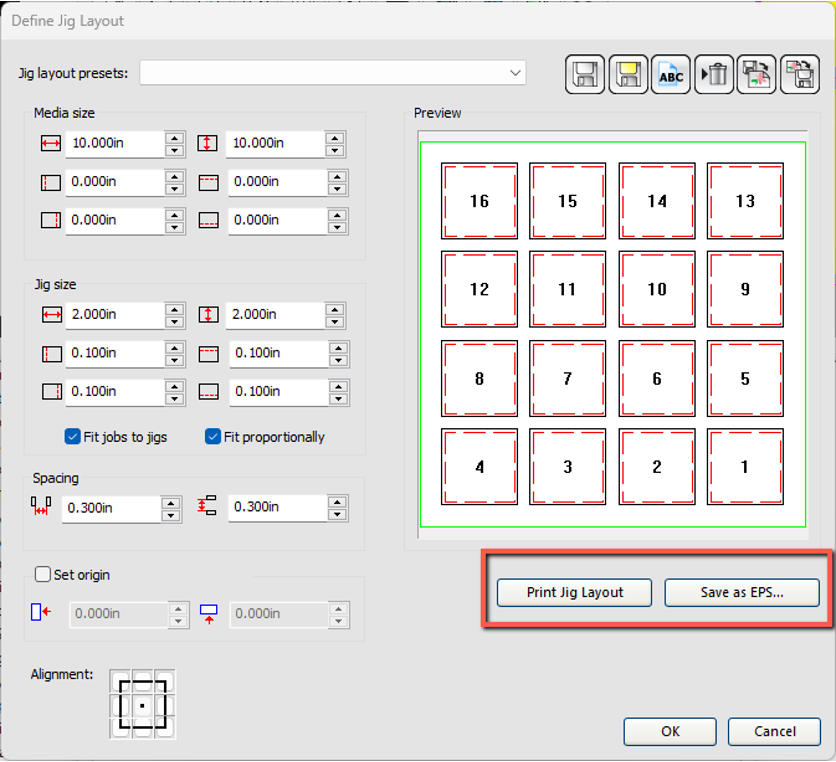
JIG Templates
Save and export JIG layouts as EPS files for creating physical
JIG parts.
We’ve added an option to “RIP Only” after receiving a job to a
hot folder. This can save you time as jobs will be ripped while
you work on preparing other print jobs.
At SAi we care about our customers,
your satisfaction is our top priority. Our team of customer
service and technical specialists, located in offices around the
world, work to provide timely answers and solutions to your
questions. We believe that support is a key component of
high-quality software and something that distinguishes SAi in
the marketplace. SAi provides support at no additional cost to
customers using the current software version and to all software
subscribers.